
In the near future (or maybe even now?), people will do their reading almost exclusively via device (i.e. on a digital reader, laptop, tablet, and/or smartphone) instead of via paper. Given this change of medium, some questions naturally follow: Should digital readers be used like traditional books (i.e. just to display text)? Or can technology be integrated into the reading experience without becoming distracting?
I propose a session in which we investigate the latter question. I believe we can create integrated text analysis and mining tools that will not only improve students’ reading comprehension but also aid anyone’s literary scholarship. I will start my session by introducing two techniques—sentiment analysis and social network extraction—that work toward this goal, and then the session will open-up into a discussion of what kinds of computational text analysis and visualization tools could be intergraded into literary analysis and the digital reading experience and how useful these tools would be. If there is interest, we could even try to hack our own text analysis / reading aide tool. Below are some examples of the capabilities of automated sentiment analysis and social network extraction.
Sentiment Analysis:
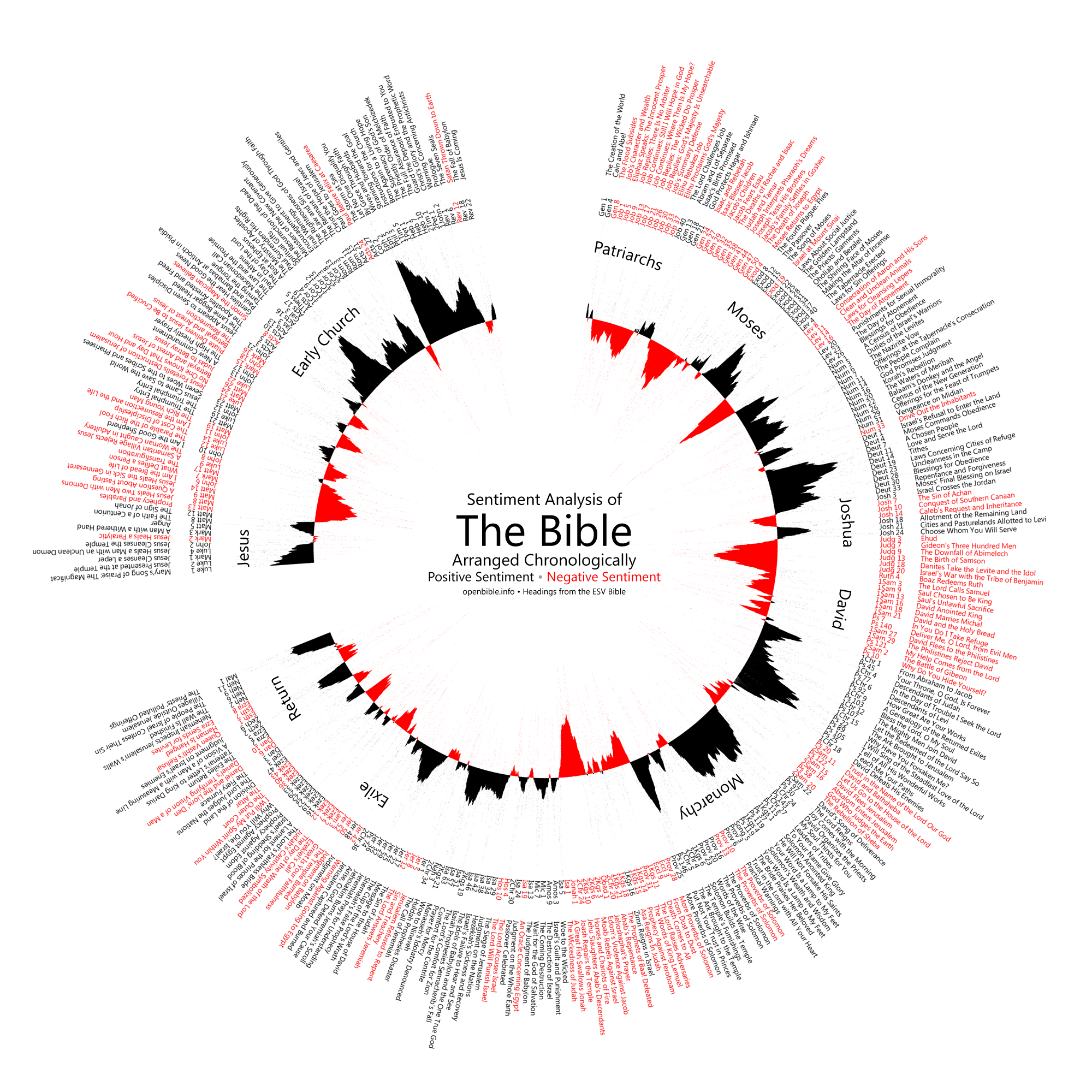
- Visualization of sentiment in the Bible: shows the old testament to be generally negative and the new testament to be generally positive.
- The picture below shows the results of sentiment analysis on Shakespeare’s Othello. Othello’s sentiment (how positive/negative he feels) towards Desdemona is algorithmically tracked over the course of the play and is represented by the black line, which we see drastically declines over time.
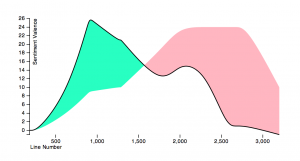
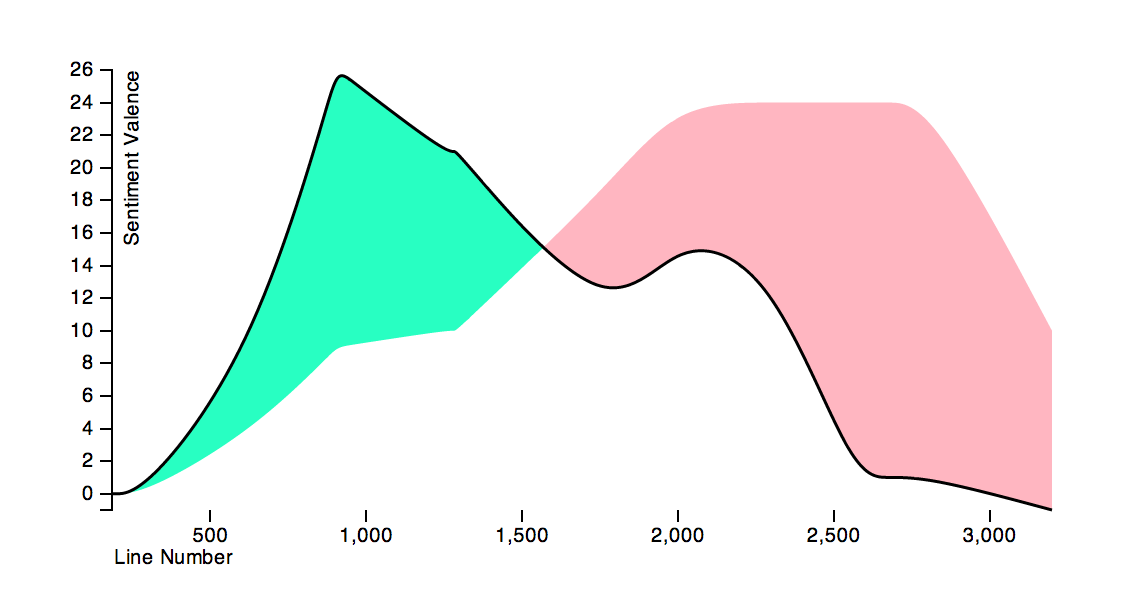
Social Network Extraction:
- A social network algorithmically extracted from Hamlet:
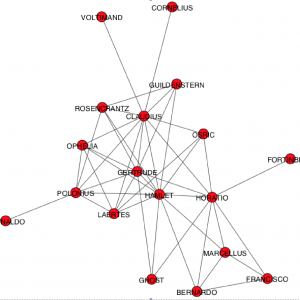


{kind=link}
Good idea, with many possible directions.
Another issue with digital readers is the choice of document size –
books are organized into chapters, web sites into pages,
but in some cases smaller pieces of content might be useful.
A few years back I advised a student project exploring paragraph wikis,
and how WikiPedia might be automatically reformatted by section/paragraph,
to encourage more lateral connections:
kussmaul.org/tiki/tiki-download_wiki_attachment.php?attId=137